什么是MFCC
MFCC(Mel-scale Frequency Cepstral Coefficients,梅尔频率倒谱系数)是一种在自动语音识别和说话人识别中广泛使用的特征。它的核心思想是依据人的听觉实验结果来分析语音的频谱,即基于人耳对不同频率声音的感知特性来提取音频特征。
为什么需要MFCC?
人耳对声音的感知并非线性的。研究发现:
- 人耳对低频声音更敏感,对高频声音较不敏感
- 人耳对频率的感知遵循梅尔刻度(Mel Scale),而非线性刻度
- 人耳具有临界带宽特性,不同频率范围有不同的分辨能力
MFCC正是模拟了这种人耳听觉机制,使得提取的特征更符合人类对声音的感知方式。
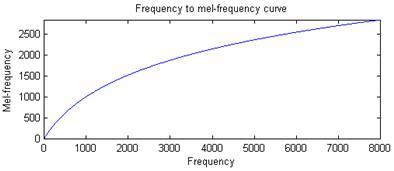
梅尔刻度
梅尔刻度定义了实际频率与人耳感知频率之间的非线性映射关系:
频率转换为梅尔频率:
$$f_{mel} = 2595 \times \log_{10}(1 + \frac{f}{700})$$
梅尔频率转换回频率:
$$f = 700 \times (10^{f_{mel}/2595} - 1)$$
从公式可以看出,低频部分变化较大,高频部分变化较小,这正符合人耳的感知特性。
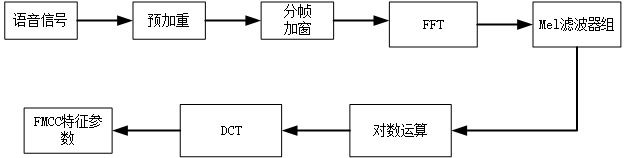
MFCC特征提取流程
完整的MFCC提取包含以下6个步骤:
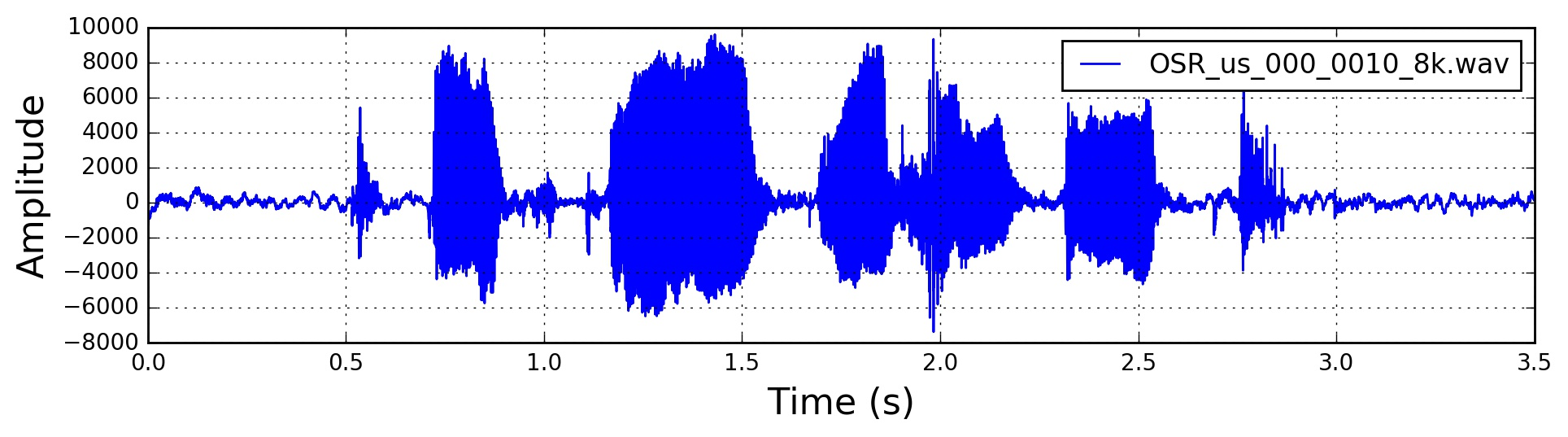
1. 预加重
对原始信号进行高通滤波,增强高频部分:
$$y(t) = x(t) - \alpha \times x(t-1)$$
其中 $\alpha$ 通常取 0.97。预加重的作用是:
- 提升高频分量,平衡频谱
- 消除声带和嘴唇的效应
- 提高信噪比
原始语音信号波形:
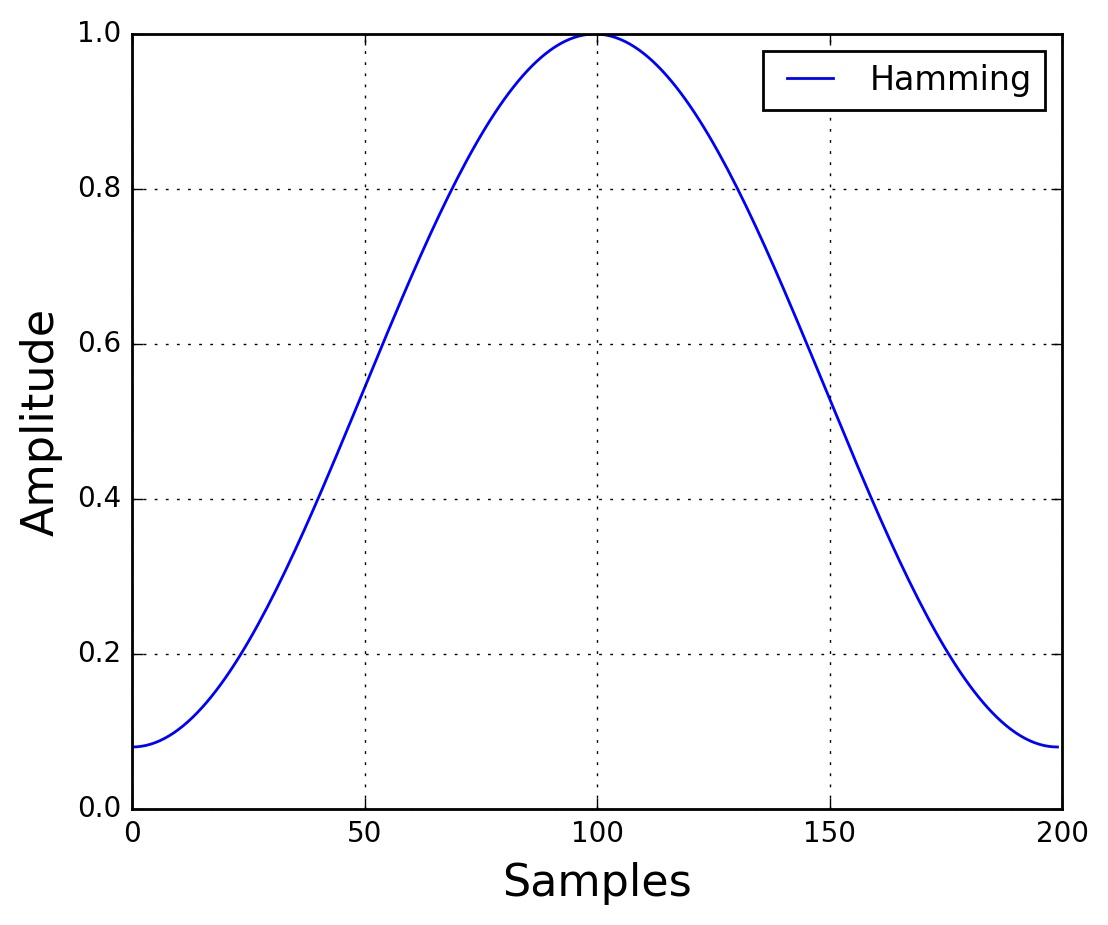
2. 分帧和加窗
分帧参数:
- 帧长:通常25ms(在8kHz采样率下为200个采样点)
- 帧移:通常10ms(80个采样点)
- 帧重叠:约50%
加窗(汉明窗):
$$W(n, a) = (1-a) - a \times \cos(\frac{2\pi n}{N-1})$$
其中 $a = 0.46$,$N$ 为帧长。加窗的目的是减少帧边界的不连续性,降低频谱泄漏。
3. 快速傅里叶变换(FFT)
对每一帧加窗后的信号进行FFT,转换到频域:
$$S_i(k) = \sum_{n=1}^{N} s_i(n) \times e^{-j2\pi kn/N}$$
其中 $N$ 通常取 256 或 512。
功率谱:
$$P = \frac{|FFT(x_i)|^2}{N}$$
4. 梅尔滤波器组
应用一组三角形滤波器,将频谱映射到梅尔刻度上。每个滤波器的频率响应为:
$$H_m(k) = \begin{cases}
0 & k < f(m-1) \
\frac{k-f(m-1)}{f(m)-f(m-1)} & f(m-1) \leq k < f(m) \
1 & k = f(m) \
\frac{f(m+1)-k}{f(m+1)-f(m)} & f(m) < k \leq f(m+1) \
0 & k > f(m+1)
\end{cases}$$
通常使用 40个 Mel滤波器。滤波后对每个滤波器的能量取对数:
$$S(m) = \ln\left(\sum_{k=0}^{N-1} |X(k)|^2 \times H_m(k)\right)$$
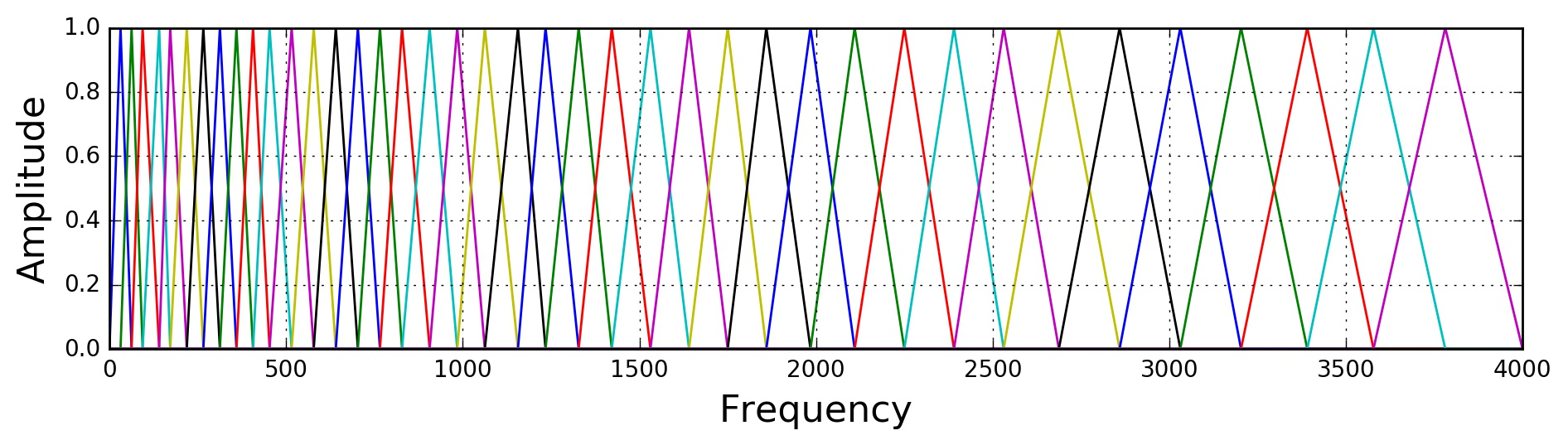
5. 离散余弦变换(DCT)
对对数能量进行DCT变换,去除滤波器组能量之间的相关性:
$$C(n) = \sum_{m=0}^{M-1} s(m) \times \cos\left(\frac{\pi n(m-0.5)}{M}\right)$$
其中:
- $n = 1, 2, …, L$(通常 $L = 12$ 或 $13$)
- $M$ 为滤波器个数
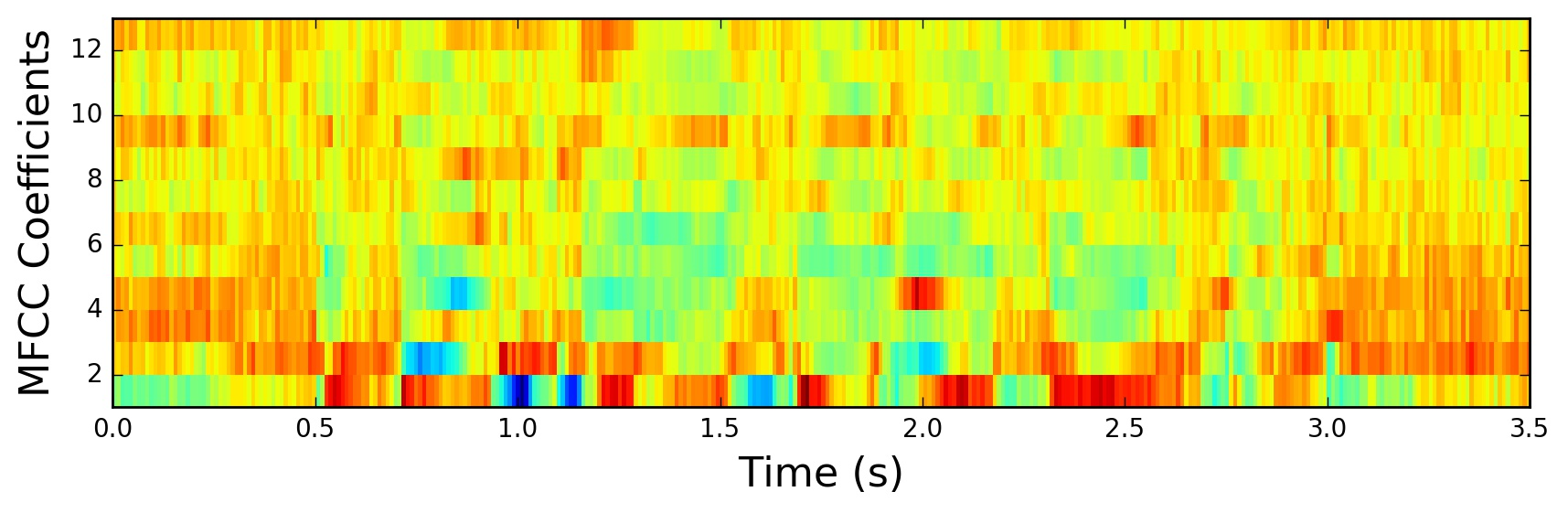
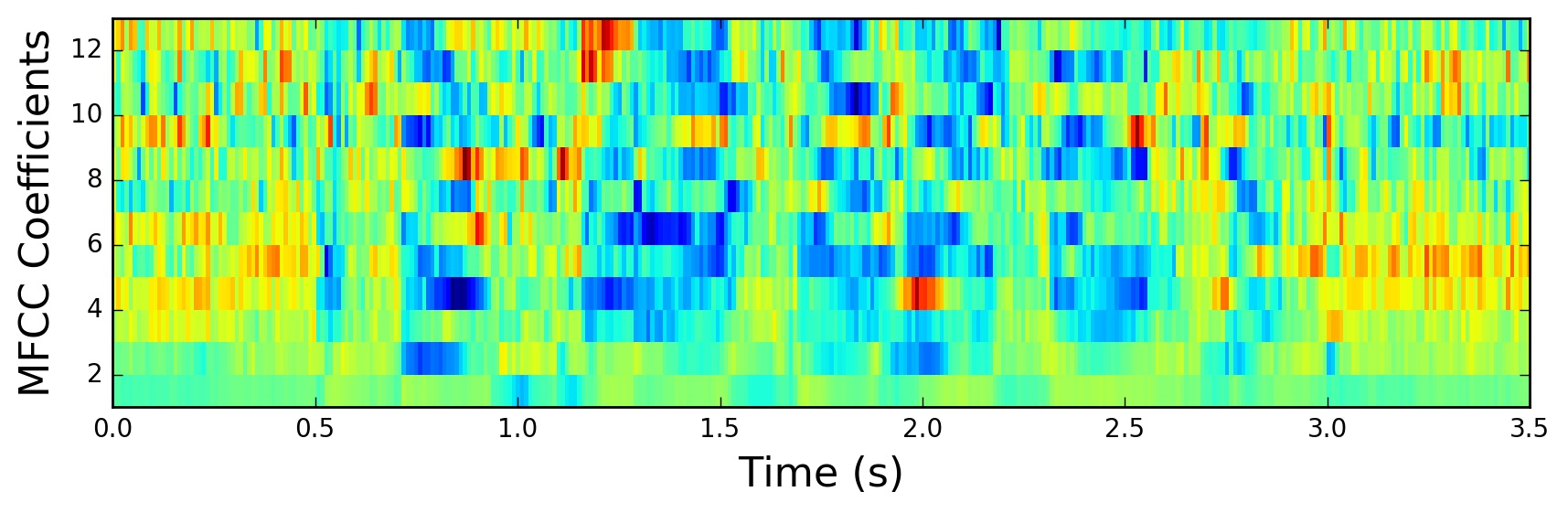
6. 保留MFCC系数
通常保留第2-13个DCT系数作为MFCC特征(第1个系数代表平均能量,常被舍弃或单独处理)。
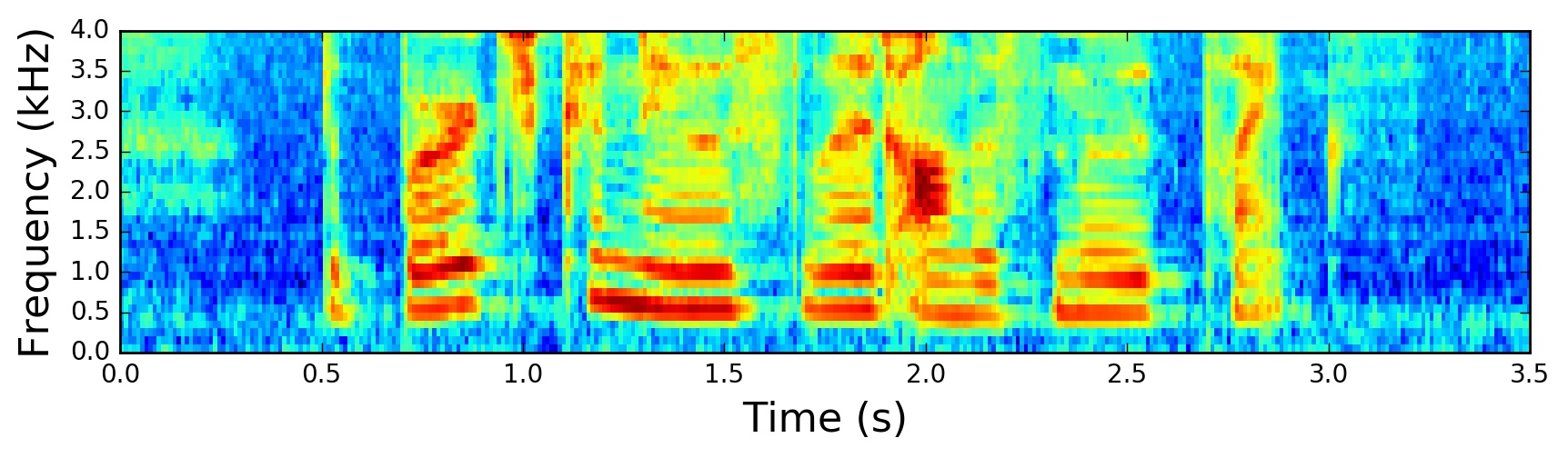
提取过程的可视化结果:
关键参数总结
| 参数 | 典型值 | 说明 |
|---|---|---|
| 预加重系数 | 0.97 | 高通滤波 |
| 帧长 | 25ms | 短时平稳假设 |
| 帧移 | 10ms | 帧间重叠 |
| FFT点数 | 512 | 频谱分辨率 |
| Mel滤波器数 | 40 | 频带划分 |
| MFCC系数数 | 12-13 | 保留2-13阶 |
Python实现
使用Librosa库(推荐)
1 | import librosa |
使用 librosa 提取的 Mel 频谱图示例:
手动实现核心步骤
1 | import numpy as np |
MFCC的应用场景
- 自动语音识别(ASR):将语音转换为文字
- 说话人识别:识别说话人身份
- 情感识别:分析语音中的情感状态
- 音乐信息检索:音乐流派分类、歌曲识别
- 语音活动检测(VAD):判断是否有人在说话
FBank vs MFCC
在深度学习时代,另一种特征**FBank(Filter Bank)**也很常用:
| 特征 | MFCC | FBank |
|---|---|---|
| 信息量 | 经过DCT压缩,信息有损失 | 保留更多信息 |
| 去相关 | DCT去相关性强 | 相邻频带有相关性 |
| 适用模型 | GMM-HMM等传统模型 | DNN/CNN/RNN等深度模型 |
| 判别度 | 判别度更好 | 需要模型自己学习 |
现代趋势:深度学习模型更倾向使用FBank特征,因为神经网络有能力从更原始的特征中学习到更好的表示。
总结
MFCC是一种经典且有效的音频特征提取方法,其核心优势在于:
- 符合人耳感知:基于梅尔刻度,模拟人类听觉系统
- 去相关性:通过DCT变换减少特征之间的相关性
- 维度合适:通常12-13维,计算高效
- 鲁棒性好:对噪声和说话人变化有一定鲁棒性
尽管在深度学习时代,端到端的学习方法可以直接从原始波形或频谱图学习特征,但MFCC作为一种精心设计的手工特征,在计算资源受限、训练数据较少的场景下仍然具有重要价值。
参考资料
- MFCC原理详解
- Mel-Frequency Cepstral Coefficients (MFCCs) - Speech Processing
- Python语音信号处理库:librosa, scipy, python_speech_features

